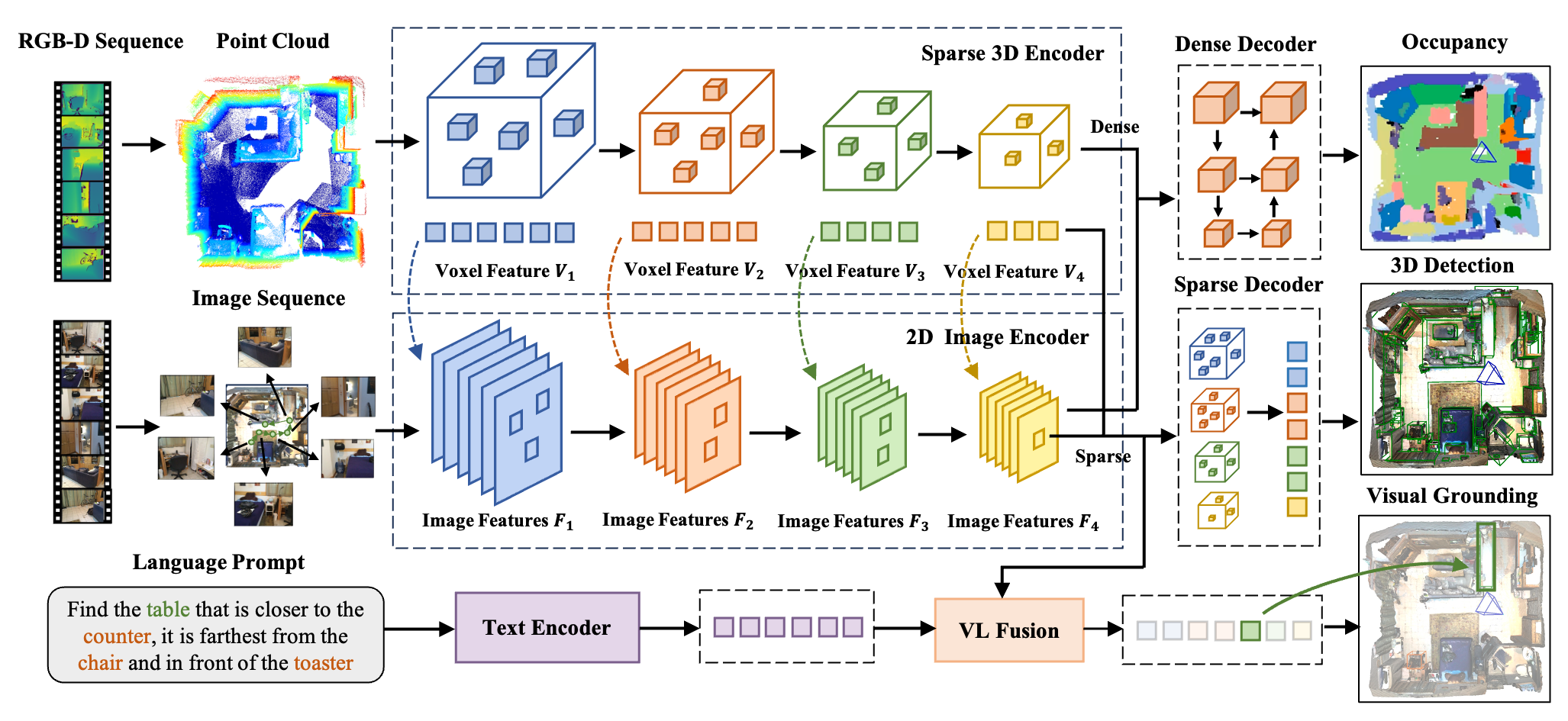
Dataset Overview
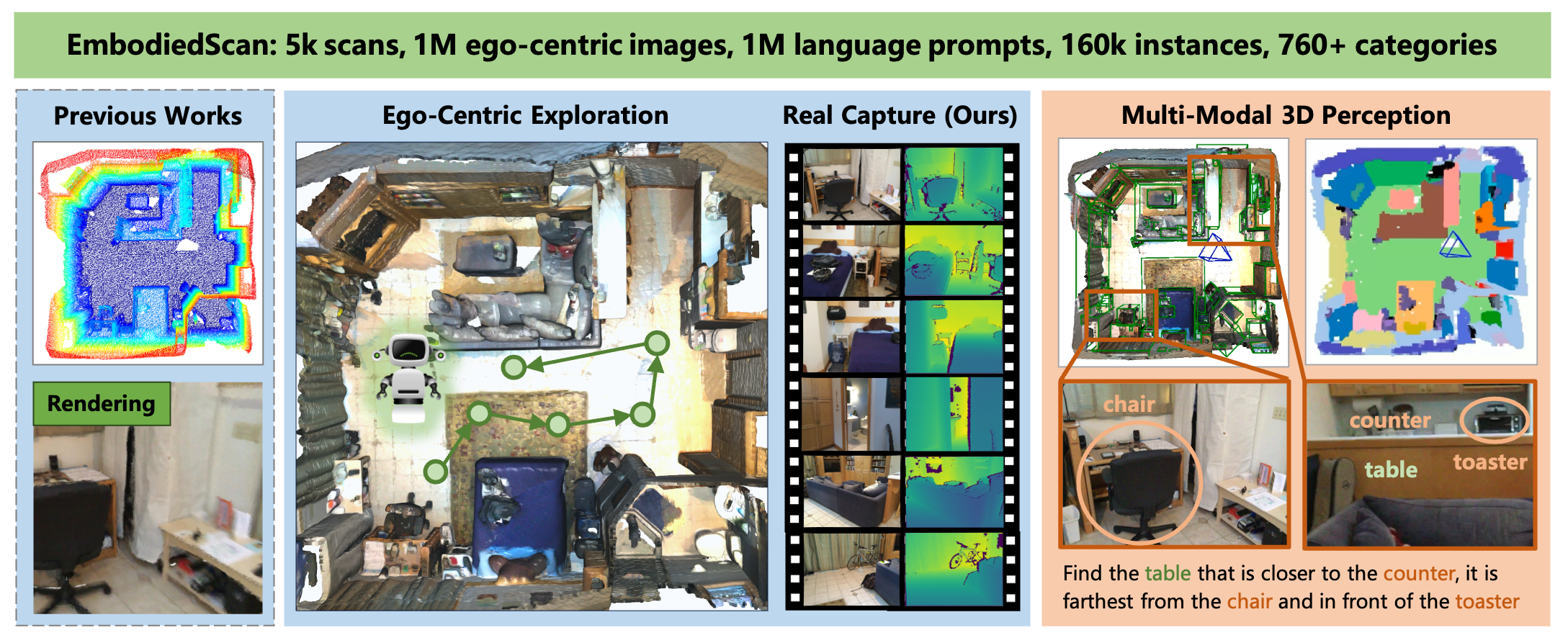
EmbodiedScan provides a multi-modal, ego-centric 3D perception dataset with massive real-scanned data and rich annotations for indoor scenes. It benchmarks language-grounded holistic 3D scene understanding capabilities for real-world embodied agents.